Is AGI Here? A Deep Dive into OpenAI’s o3 Model and ARC-AGI Benchmarks

Independent AI researcher, software developer, and systems designer with expertise in scalable AI workflows, web development, and network infrastructure design. Sharing insights on tech, innovation, and AI's transformative power.
Artificial General Intelligence (AGI) is one of the most fascinating — and fear-inducing — concepts in modern technology. The idea of machines capable of understanding, learning, and performing any intellectual task a human can conjure has captured imaginations and sparked existential concerns. Recent advancements, such as OpenAI’s o3 model surpassing the human-level threshold on the ARC-AGI benchmark, have fueled speculation that AGI is no longer a distant dream. But with such excitement comes fear: What happens when machines become as intelligent — or more so — than humans? Will humanity lose control of its creations?
The truth, however, is far more complex and reassuring. While the o3 model’s achievements are undeniably groundbreaking, misconceptions about its significance have led many to mistakenly equate this progress with the arrival of AGI. These misunderstandings reveal not only a lack of clarity about what AGI truly entails but also a need to better understand the tools and benchmarks driving AI development today. To separate fact from fiction, we must delve into what ARC-AGI is, why it was created, and how OpenAI’s relationship with this benchmark reflects the real state of AGI.
To uncover the reality behind the hype, let’s explore the history and purpose of the ARC-AGI benchmark and its role in advancing artificial intelligence.
Origins and Objectives of the ARC AGI Benchmark

History and Purpose
The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) benchmark was introduced in 2019 by François Chollet, the creator of the Keras deep-learning library. Its primary purpose is to evaluate an AI system’s ability to reason and generalize across novel tasks — a key characteristic of human intelligence. Unlike traditional benchmarks that test narrow capabilities, ARC-AGI aims to measure cognitive processes like abstraction, inference, and pattern recognition. By focusing on these abilities, ARC-AGI serves as a foundational tool for gauging progress toward general AI.
Key Features
ARC-AGI is composed of abstract puzzles that are designed to challenge models in unique ways. These puzzles:
Require models to infer underlying rules and apply them without relying on brute-force computation or training data.
Prioritize problem-solving over memorization, making them a unique challenge for even the most advanced AI systems.
Eliminate reliance on vast datasets by focusing solely on reasoning and generalization.
The benchmark’s design ensures that only systems capable of adapting to new scenarios can succeed, offering a clear distinction between narrow AI capabilities and steps toward broader general intelligence.
Broader Role in AI Development
ARC-AGI was created to address a critical gap in AI research: the need to differentiate between systems that excel through sheer data memorization and those capable of genuine reasoning. In an era where AI models often achieve success through extensive data training, ARC-AGI challenges systems to demonstrate adaptability — a key requirement for any system aspiring to achieve AGI.
However, it is equally important to understand what ARC-AGI does not measure. It doesn’t evaluate emotional intelligence, real-world adaptability, or dynamic memory recall, which are often conflated with AGI readiness in public discourse. Instead, it provides a focused assessment of reasoning skills, serving as one piece of the larger puzzle in AI advancement.
OpenAI and ARC AGI

OpenAI and ARC-AGI Working Together
Timeline of Collaboration
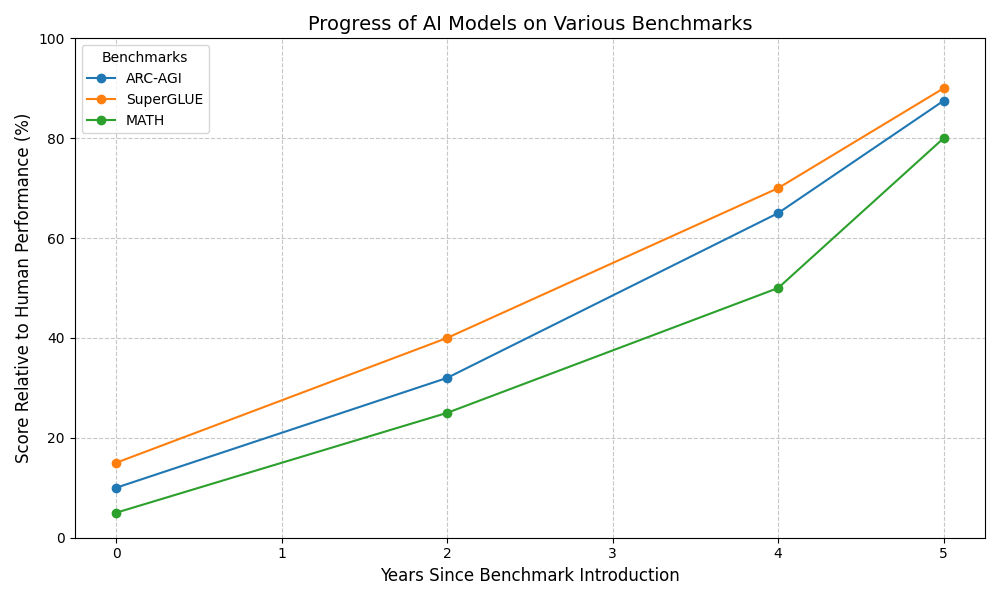
OpenAI’s engagement with ARC-AGI began with the o1 model, released in September 2024. Scoring approximately 32% on the ARC-AGI benchmark, the o1 model revealed the complexity of the tasks and highlighted the limitations of early AI systems in generalizing beyond narrowly defined parameters. Despite its modest performance, it set a foundation for iterative improvements.
The December 2024 release of the o3 model marked a significant breakthrough. With a record-breaking score of 87.5% in high-compute scenarios, the o3 model surpassed the human-level performance threshold of 85%. This achievement demonstrated remarkable progress in reasoning capabilities, showcasing OpenAI’s ability to refine and advance its models in alignment with ARC-AGI’s stringent demands.
Significance of the Partnership
The partnership between OpenAI and ARC-AGI goes beyond routine testing. By leveraging ARC-AGI, OpenAI has been able to evaluate and enhance its models systematically, focusing on their ability to generalize and solve novel problems. This collaborative effort has provided researchers with valuable insights into the strengths and limitations of current AI systems.
However, while OpenAI’s models excel in reasoning tasks as demonstrated by ARC-AGI, they remain far from achieving AGI. These systems do not exhibit the broad cognitive abilities or real-world adaptability necessary for AGI, reminding us that ARC-AGI measures a crucial but narrow aspect of intelligence. This distinction underscores the importance of benchmarks in advancing research while maintaining realistic expectations about AI’s current capabilities.
Addressing Misconceptions About AGI
Let’s find out the difference between AI and AGI
Benchmark vs. AGI
A high score on the ARC-AGI benchmark, such as the 87.5% achieved by OpenAI’s o3 model, is an impressive feat, but it does not signify the arrival of Artificial General Intelligence. ARC-AGI evaluates reasoning in controlled scenarios, focusing narrowly on abstract problem-solving. True AGI, however, would require a much broader set of capabilities, including adaptability, emotional intelligence, and self-directed learning — qualities not captured by benchmarks like ARC-AGI.
Expert Perspectives
François Chollet, the creator of ARC-AGI, has repeatedly emphasized that while benchmarks provide valuable insights into reasoning, they only represent a fragment of what constitutes general intelligence. Experts widely agree that AGI would need to exhibit skills far beyond the controlled environments of benchmark tests, such as the ability to integrate diverse knowledge, contextualize problems, and operate autonomously in complex, real-world scenarios.
Current State of AI
Today’s AI systems, including OpenAI’s advanced o3 model, remain firmly in the domain of narrow AI. They excel in specific tasks, such as reasoning through abstract puzzles, but lack the capacity for generalization required to tackle diverse, unstructured challenges. This gap between current AI capabilities and the theoretical goals of AGI underscores the importance of managing expectations. While benchmarks like ARC-AGI help advance reasoning skills, they highlight how much further the field has to go before true general intelligence can be realized.
Root Causes of Public Misconceptions
Much of the confusion surrounding AGI stems from sensationalized media coverage that often oversells the capabilities of advanced AI models. Headlines proclaiming “AGI is here” leverage attention-grabbing narratives but fail to clarify the nuanced distinctions between narrow AI and AGI. This contributes to inflated expectations and a lack of understanding about what AGI would truly require, such as emotional comprehension and autonomous adaptability. Misaligned perceptions can hinder public discourse and create unnecessary fear about AI’s trajectory, underscoring the need for clearer communication from researchers and media alike.
Broader Implications of AI Benchmarks

What are The Broader Implications of AI Benchmarks
Driving AI Progress
ARC-AGI and similar benchmarks serve as critical tools for driving advancements in artificial intelligence. By providing clear, measurable goals, they encourage researchers to push the boundaries of what AI can achieve. ARC-AGI’s emphasis on reasoning and generalization has fostered breakthroughs in how AI systems approach abstract problem-solving, contributing to improved models that can better navigate novel tasks. These incremental improvements have applications far beyond research, benefiting industries such as healthcare, transportation, and education.
Limitations of Benchmarks
While benchmarks like ARC-AGI are instrumental in evaluating specific capabilities, they are not comprehensive measures of intelligence. ARC-AGI, for example, focuses on reasoning skills but does not address emotional intelligence, dynamic memory recall, or contextual adaptability — qualities essential for AGI. This limitation underscores the need for complementary evaluation tools that can measure broader cognitive capabilities as AI continues to evolve.
Guiding Research and Public Perception
Benchmarks also play a pivotal role in shaping research priorities and public understanding of AI. Misinterpreting high scores as signs of AGI can create unrealistic expectations, but when used appropriately, benchmarks like ARC-AGI provide a grounded framework for discussing AI’s capabilities and limitations. By establishing clear milestones, they help researchers communicate progress transparently while tempering public speculation. This fosters a more informed dialogue about the trajectory of AI development and its potential to transform society responsibly.
Conclusion
The journey toward Artificial General Intelligence is one filled with excitement, misunderstanding, and incremental progress. While models like OpenAI’s o3 have achieved groundbreaking results on benchmarks like ARC-AGI, these advancements are stepping stones, not destinations. ARC-AGI’s narrow focus on reasoning highlights critical progress in AI, but it also underscores the limitations that remain before AGI becomes a reality.
Public misconceptions often blur the distinction between narrow AI and AGI, fueled by sensationalized media and misinterpreted benchmarks. These misunderstandings emphasize the importance of fostering transparent communication about what current AI systems can and cannot do. By addressing these misconceptions, we can encourage more informed and constructive discussions about AI’s potential and its trajectory.
Benchmarks like ARC-AGI provide a valuable framework for assessing AI’s progress, setting achievable milestones that guide research while tempering expectations. However, achieving AGI will require breakthroughs that extend far beyond these evaluations, encompassing emotional intelligence, contextual understanding, and real-world adaptability.
As we look ahead, it is crucial to remain both optimistic and realistic. AI continues to evolve at a remarkable pace, offering transformative possibilities for society. However, the road to AGI is long and uncertain, requiring collaboration, responsible innovation, and a deep commitment to understanding the complexities of intelligence itself. The promise of AGI lies not in headlines, but in the careful, deliberate work that will define the future of artificial intelligence.
Glossary
Artificial General Intelligence (AGI): A theoretical form of AI that can understand, learn, and apply knowledge across a wide range of tasks at a human level of competency, exhibiting adaptability and reasoning capabilities akin to human intelligence.
ARC-AGI Benchmark: The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI), introduced by François Chollet in 2019, is a benchmark designed to evaluate an AI system’s ability to generalize and adapt to novel tasks, focusing on reasoning and problem-solving skills.
Narrow AI: AI systems designed to perform specific tasks exceptionally well, such as language translation or image recognition, without the ability to generalize across different tasks.
Reasoning Capabilities: The ability of AI systems to solve problems, infer rules, and make decisions based on logic and patterns, often assessed through benchmarks like ARC-AGI.
Generalization: An AI’s capacity to apply learned principles and knowledge to unfamiliar tasks or scenarios beyond its training data.
Emotional Intelligence: The capability to recognize, understand, and respond to emotions in oneself or others. While often attributed to humans, some research explores its application in AI systems.
Dynamic Memory Recall: The ability of a system to adaptively retrieve and use information from memory in a fluid and context-dependent manner, essential for complex problem-solving.
Contextual Adaptability: The capability of AI systems to adjust their behavior based on nuanced understanding of different environments or scenarios.
o1 Model: An earlier iteration of OpenAI’s models tested on ARC-AGI, achieving a modest performance of 32%, highlighting the complexity of the benchmark’s tasks.
o3 Model: OpenAI’s advanced AI model that achieved a record-breaking score of 87.5% on ARC-AGI, demonstrating significant advancements in reasoning capabilities.
François Chollet: Creator of the Keras deep-learning library and the ARC-AGI benchmark. Known for contributions to AI reasoning and evaluation frameworks.
SuperGLUE Benchmark: A benchmark designed to evaluate AI systems on natural language understanding tasks. Often used alongside ARC-AGI to measure reasoning and comprehension in AI.
MATH Benchmark: A benchmark used to evaluate AI’s capability in solving mathematical problems, ranging from basic arithmetic to advanced algebra and calculus.
Human-Level Performance Threshold: A benchmark-specific score threshold indicating performance comparable to that of an average human. In the case of ARC-AGI, this threshold is set at 85%.
FAQ
What is AGI, and how is it different from Narrow AI?
Answer: Artificial General Intelligence (AGI) refers to a theoretical AI system capable of understanding, learning, and performing any intellectual task that a human can, with the ability to generalize across domains. In contrast, Narrow AI is designed to excel at specific tasks, such as language translation or image recognition, but cannot generalize beyond its training.
Does achieving a high score on ARC-AGI mean AGI is here?
Answer: No, a high score on ARC-AGI demonstrates significant progress in reasoning capabilities but does not equate to achieving AGI. ARC-AGI evaluates specific cognitive abilities in controlled scenarios, while AGI would require emotional intelligence, contextual adaptability, and the ability to generalize across unstructured tasks.
What is the ARC-AGI benchmark, and why is it significant?
Answer: ARC-AGI (Abstraction and Reasoning Corpus) is a benchmark introduced by François Chollet in 2019 to evaluate an AI’s ability to generalize and reason through abstract tasks. It’s significant because it challenges AI systems to demonstrate adaptability and problem-solving beyond rote memorization, offering a clearer path toward understanding general intelligence.
What was OpenAI’s o3 model’s performance on ARC-AGI?
Answer: OpenAI’s o3 model achieved a record-breaking score of 87.5% on ARC-AGI, surpassing the human-level performance threshold of 85%. This result highlights remarkable advancements in reasoning but remains within the scope of Narrow AI capabilities.
Why do people misunderstand AI advancements as AGI?
Answer: Misconceptions often arise from sensationalized media coverage that oversimplifies AI progress. Benchmarks like ARC-AGI are sometimes misinterpreted as evidence of AGI, leading to inflated expectations and confusion about the actual capabilities of Narrow AI systems.
What are the broader implications of benchmarks like ARC-AGI?
Answer: Benchmarks like ARC-AGI drive innovation by setting measurable goals for AI development, pushing boundaries in reasoning and generalization. However, they also have limitations, as they don’t evaluate emotional intelligence, real-world adaptability, or broader cognitive abilities required for AGI.
When can we expect AGI to become a reality?
Answer: AGI remains a theoretical concept, and its timeline is uncertain. Significant breakthroughs in areas like emotional intelligence, real-world adaptability, and dynamic memory recall are needed before AGI becomes achievable. Current AI systems, including advanced models like o3, are still far from AGI capabilities.
How do ARC-AGI benchmarks impact real-world AI applications?
Answer: ARC-AGI benchmarks impact real-world AI applications by pushing the boundaries of what AI systems can achieve in terms of reasoning and adaptability. These benchmarks encourage the development of models that excel at solving novel problems, which can translate to improved AI systems for fields like healthcare, where diagnostic tools must handle unforeseen cases, or transportation, where autonomous systems must adapt to changing conditions. By emphasizing generalization and reasoning, ARC-AGI fosters AI advancements that are not just powerful in controlled environments but also robust and versatile in practical applications.
What role does emotional intelligence play in AGI?
Answer: Emotional intelligence would enable an AI to recognize, understand, and respond to emotions, allowing for more human-like interactions. It’s a critical component for AGI but remains largely unexplored and undeveloped in current AI systems.
Related Sources
Gorombo: Streamlining AI and Web Development Workflows
Gorombo offers a suite of services focused on improving efficiency, scalability, and workflow optimization through AI-driven solutions and custom web development.
Dan Sasser’s Blog: Insights on AI Research and AGI Misconceptions
Check in with Dan to keep up to date on the latest tech trends and to learn about a wide variety of topics.
ARC Prize Official Website
Provides comprehensive information on the ARC-AGI benchmark and the associated competition aimed at advancing AI research.
GitHub Repository for ARC-AGI
Offers access to the ARC-AGI task data and a browser-based interface for manual problem-solving, facilitating a deeper understanding of the benchmark’s structure.
On the Measure of Intelligence” by François Chollet
A foundational paper discussing the principles behind the ARC-AGI benchmark and the broader context of evaluating AI intelligence.
OpenAI’s o3 Model Announcement
Details OpenAI’s o3 model, its performance on the ARC-AGI benchmark, and its implications for AI development.
ARC Prize 2024: Technical Report
An in-depth analysis of the ARC-AGI benchmark’s status as of December 2024, discussing its significance and the challenges it presents.
LLMs are a Dead End to AGI, says François Chollet
An article exploring Chollet’s perspective on the limitations of large language models in achieving AGI and the role of benchmarks like ARC-AGI.
OpenAI’s o3 Sets New Record, Scoring 87.5% on ARC-AGI Benchmark
A report highlighting the o3 model’s achievement and its implications for the future of AI research.
ARC Prize — a $1M+ Competition Towards Open AGI Progress
A discussion on the ARC Prize initiative, its goals, and its impact on the AI research community.
OpenAI’s o3 Model Breaks Ground with High ARC Score, Yet AGI Still Out of Reach
An analysis of the o3 model’s performance and the ongoing challenges in achieving true AGI.
OpenAI Releases o3 Model With High Performance and High Cost
An article discussing the capabilities and resource demands of OpenAI’s o3 model, providing context on the trade-offs in advanced AI development.
References
François Chollet. “ARC: The Abstraction and Reasoning Corpus.” (2019). Available at: https://arc-benchmark.com
- Explains the purpose and design of the ARC-AGI benchmark and its role in evaluating reasoning capabilities in AI systems.OpenAI Blog. “Introducing o3: Breaking Records on ARC-AGI.” (2024). Available at: https://openai.com
- Details the release of the o3 model and its performance on the ARC-AGI benchmark, including its record-breaking score.François Chollet. “Why Benchmarks Matter and Their Limitations in Measuring Intelligence.” (2023). Available at: https://francoischollet.com/benchmarks
-Discusses the limitations of benchmarks like ARC-AGI in defining true general intelligence and the need for broader evaluations.Wired. “The Rise of o3 and the Path Toward General AI.” (2024). Available at: https://wired.com
- Analyzes OpenAI’s advancements and how benchmarks like ARC-AGI drive innovation while clarifying misconceptions about AGI.TechCrunch. “AI Benchmarks and Public Misconceptions: Why We’re Far From AGI.” (2024). Available at: https://techcrunch.com
- Explores the public’s misunderstanding of AI achievements and how benchmarks like ARC-AGI fuel both progress and unrealistic expectations.François Chollet. “Insights on AGI and the Future of AI Research.” (2023). Available at: https://keras.io/blog
- Provides expert insights into AGI’s theoretical state and the steps needed to bridge the gap between narrow AI and true general intelligence.
Support My Work
If you enjoyed reading this article and want to support my work, consider buying me a coffee and sharing this article on social media!

